What this article is and it is not
This short article is not about giving in depth details about how sync or async mechanisms work. It covers fallacies and struggles with each approach.
Its main purpose is to raise awareness, to make one take a step back and think about how irrespective of the communication mechanism choices, the resiliency and the scalability of a distributed system can be ensured.
Sync and Async Communication Mechanisms
Synchronous behavior is when the application constructs a request, sends over the connection, and waits for the response (blocking the execution). It also means connected or dependent in some way
Asynchronous behavior is when the application constructs the request, sends out, and moves on. It has a separate logic (a thread) listening to the connection, waiting for the response, and acting on it when it arrives.
Fallacies of Distributed Systems
The fallacies of distributed computing are a set of assertions made by L Peter Deutsch and others at Sun Microsystems describing false assumptions that programmers new to distributed applications invariably make.
The fallacies are[1]
- The network is reliable;
- Latency is zero;
- Bandwidth is infinite;
- The network is secure;
- Topology doesn’t change;
- There is one administrator;
- Transport cost is zero;
- The network is homogeneous.
Why do those matter?
Ignoring the above, and building distributed systems with the hope for the best can bring them to a point of failure which can be difficult to comprehend and fix. Data inconsistencies, partial successes, lost calls are tricky to figure out.
Reliable Systems & Resiliency
Reliable Systems should continue to work correctly (performing the correct function at the desired level of performance) even in the face of adversity (hardware or software faults, and even human error
The things that can go wrong are called faults(hardware / software / human), and systems that anticipate faults and can cope with them are called fault-tolerant or resilient
There are situations in which we may choose to sacrifice reliability in order to reduce development cost but we should be very conscious of when we are cutting corners.
Synchronous Communication
SIMPLER, straightforward
STRICT
- Synchronous programming functions as a one-track mind, checking off one task at a time in a rigid sequence.
Resource Intensive, Blocking, Leads to Low Performance:
- HTTP is synchronous and the original request doesn’t get a response until all internal HTTP calls are finished. It’s fine until the request calls increase and one of them is blocked. In such a situation, the performance is exponentially affected as additional HTTP requests increase.
Loss of Autonomy:
It would be ideal for in a microservices architecture, that services don’t know about one another.
If they connect through HTTP they can not be autonomous in any way.
Complex Failure Management:
- If you have a request HTTP call chain and an intermediate microservice fails, all the chain fails. Unless you have a retry scenario with a good circuit breaker strategy to recover such failures. But as the chains get more complex, implementing such a failure strategy gets so hard and in some cases impossible.
Ensuring Resiliency with Sync
What can go wrong:
Network Failures
Timeouts
One service can be down( due to hardware crashes / service crashes/ load / …)
Poor logging system, difficult to say which service in the chain actually causes the failures
etc…
Resilience Support Mechanisms:
Retry Mechanisms
Retry with Backoff Strategies
Circuit Breakers, Rate limiting
Multi availability zone deployments
Multiple instances available for one service
Master - Read Replicas for Databases
Load balancing
etc…
Sync use-cases
Synchronous programming is best utilized in reactive systems. When some actions have to all happen together to avoid for example race conditions or inconsistencies.
Sync Example
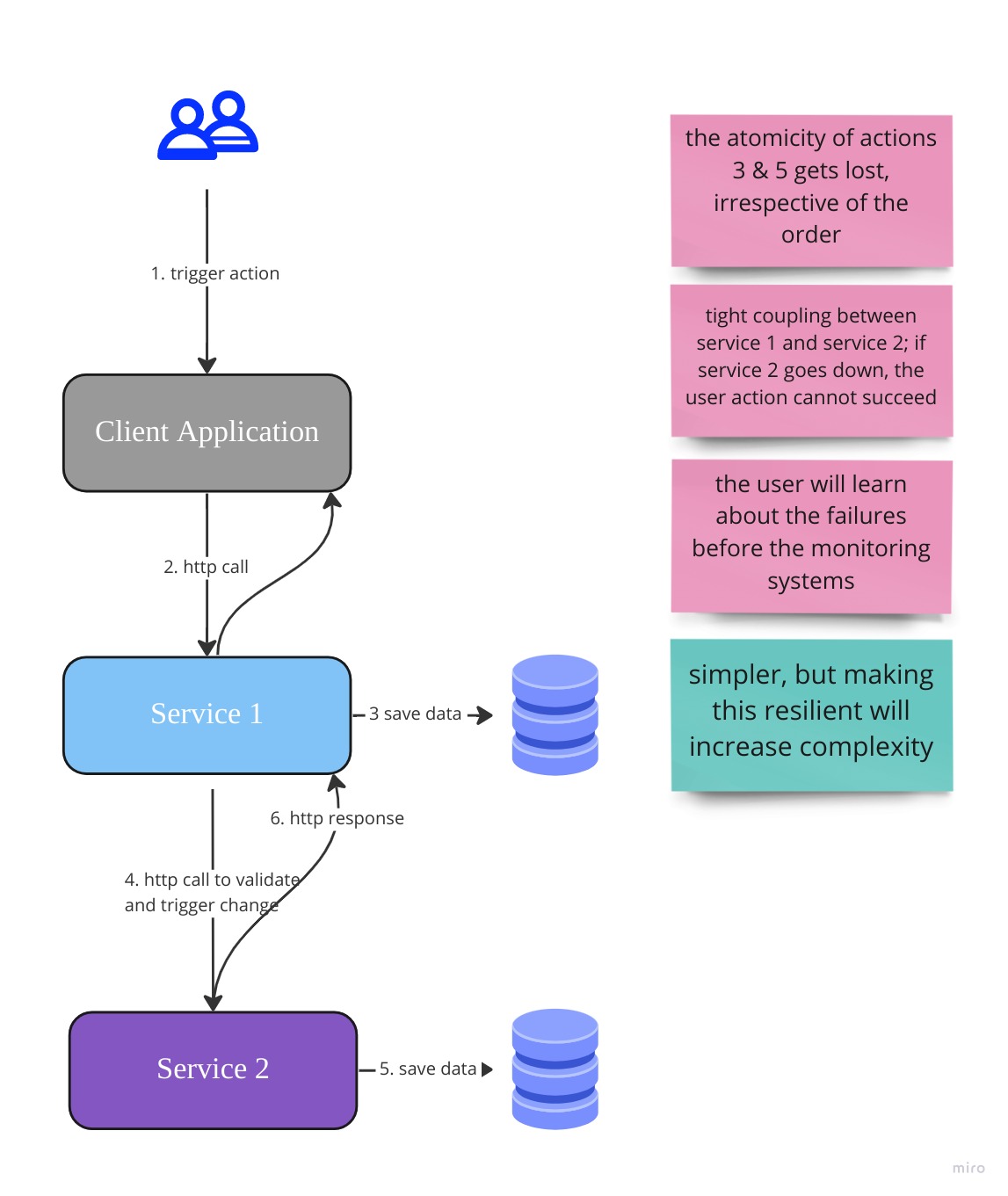
Asynchronous Communication
COMPLEX
ADAPTABLE
Asynchronous programming is the multitasker, moving from one to-do to the other and alerting the system when each one is complete.
NON BLOCKiNG
Ensures the services separation, autonomy, independence
- Ex in messaging/events driven systems: separation between producer /consumer
Messaging, Events based Systems / Webhooks / allow each service to process data on their own peace
Allows automatic up/down scale to cope with increased loads
Reduces the need to loop and perform unnecessary calls
Reduces the risks of domino effects
There are cases in which the users may not even be aware as partial degradation may be supported
Ensuring Resiliency with Async
The mechanism itself is already ensuring support. Each service just needs to ensure its own reliability in functionality & processing / publishing messages
Async use-cases
Multitask based processes, moving from one to-do to the other and alerting the system when each one is complete.
Asynchronous programming allows more things to be done at the same time and is typically used to enhance the user experience by providing an effortless, quick-loading flow.
Async example
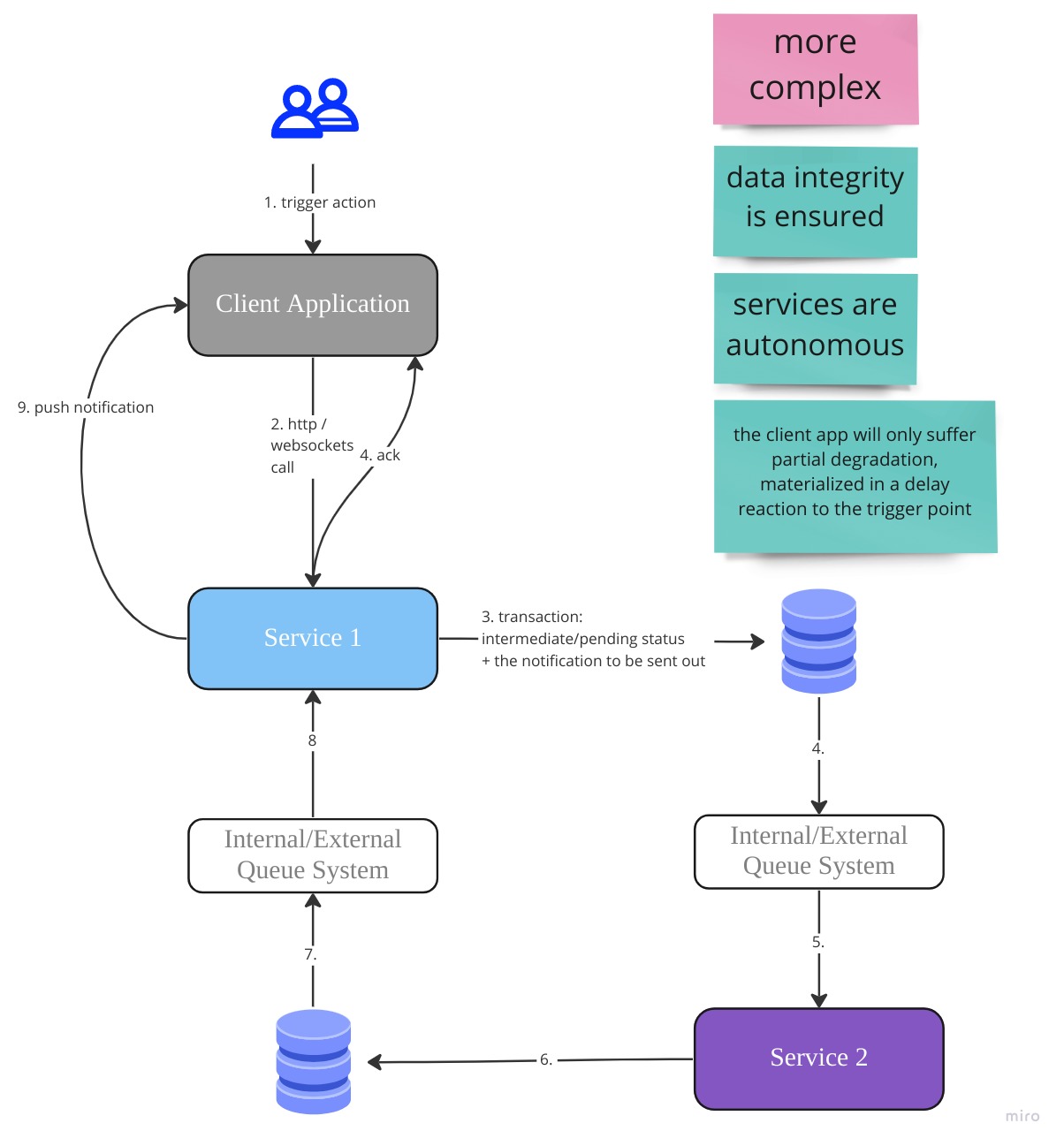
Conclusions / Recommendations
Independent on the decision, take it informed and make sure the resiliency is ensured!
Main goal is to reduce chain related failures!
If possible, never depend on synchronous communication (request/response) between multiple microservices, not even for queries. The goal of each microservice is to be autonomous and available to the client consumer, even if the other services that are part of the end-to-end application are down or unhealthy.
The goal is to find the right balance and combine these architecture patterns and communication styles. Choose the model in harmony with the problem but stay vigilant and understand the pros and cons of each.
Additional Resources
Fallacies of distributed computing