This blog post is about the step by step journey on how to tackle and discover memory leaks related issues.
Inception
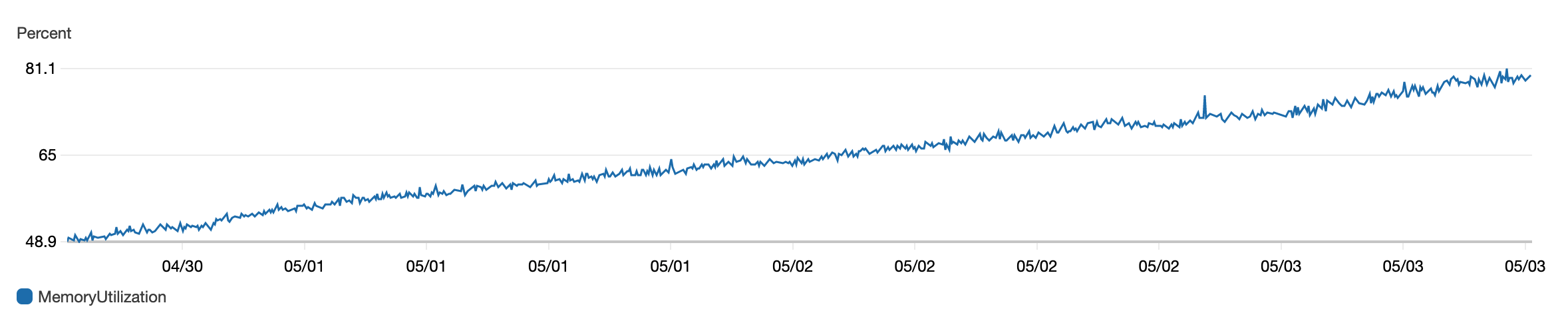
Once pictures like the below one are starting to appear in one or all of your services then it is a clear indication that something is wrong.
Especially if the service gets redeployed on a regular basis, every 2 days.
Question is what do to next?
Investigation Approaches
First step is to check all other graphs for the related matter, in order to try to reduce the area of investigation.
It goes without saying that the next most important things to do varies depending on your business and service implementation.
In my particular case, I discovered the memory growth was also reflected in the ETS table, which helped directing the investigations to a targeted area.
Finding the Problem
For finding the problem in ETS, various checks can be performed on an active node.
Filtering all ets related processes with info about their memory allocation:
ets_processes = :ets.all() |> Enum.map(fn p -> :ets.info(v) end) |> Enumm.sort(&(&1[:memory] >= &2[:memory])) |> Enum.map(fn p -> {p[:owner], Process.info(e[:owner])} end)
Depending on the result information, further filtering can be performed, in this particular case, it became obvious there is a problem at the DBConnection level.
For periodic snapshot checks, further checks were carried on.
db_conn_processes = :ets_processes |> Enum.filter(fn {_pid, v} -> v |> Keyword.get(:dictionary, []) |> Keyword.get(:"$initial_call") == {DBConnection.Connection, :init, 1} end) |> List.first()
db_conn_processes |> Enum.map(fn {pid, _p} -> :sys.get_state(pid) end) |> Enum.reduce(0, fn %Connection{mod_state: %{state: %{cursors: cursors}}}, acc -> acc + Enum.count(cursors) end)
With the above queries, I managed to understand that for some reasons, the amount of cursors in the DBConnection keeps increasing, without cleaning up.
#Reference<0.3571010832.1130627074.258072> => {:column_defs,
[
{:column_def, ...},
{...},
...
], 292},
#Reference<0.3571010832.1130364930.175393> => {:column_defs,
[
{:column_def, "uuid", ...},
{:column_def, ...},
{...},
...
], 92},
#Reference<0.3571010832.1131151361.167112> => {:column_defs,
[{:column_def, "id", ...}, {:column_def, ...}, {...}, ...], 462},
#Reference<0.3571010832.1130364930.213027> => {:column_defs,
[{:column_def, ...}, {...}, ...], 116},
#Reference<0.3571010832.1130889218.13300> => {:column_defs,
[{...}, ...], 302},
#Reference<0.3571010832.1130889218.3795> => {:column_defs, [...], ...},
#Reference<0.3571010832.1131151362.170979> => {:column_defs, ...},
#Reference<0.3571010832.1131413506.206247> => {...},
...
},
Understanding and Reproducing the Problem
I would not lie, that identifying the piece of code causing the above, was part luck part understanding what the service did.
As we had only two recurrent processes being triggered on a regular basis via a cron job, I decided to check that part of the code, and try to dig down the rabbit hole.
That being said, first action was to cancel each periodic job to check if the problem disappears, which to my luck it did.
This action further reduced my area of investigations, making me check a limited piece of code, which piece by piece could reproduce the problem.
def run() do
current_date = DateTime.utc_now()
query =
from(m in Model,
where: m.status != "expired",
where: fragment("TIMESTAMPDIFF(SECOND, ?, ?)", ^current_date, m.expires_at) < 0
)
stream =
query
|> Repo.stream()
|> Task.async_stream(fn _model -> :ok end)
Repo.transaction(fn -> Stream.run(stream) end)
end
The Fix
As it turned out above, the fix was beyond the custom service implementation, as it had to be related to either ecto or the mysql adapter.
Next step was just creating an issue in the main elixir libraries: https://github.com/elixir-ecto/ecto/issues/3311
Following the thread, you can notice Jose Valim jumped in to help in matter of minutes, and indeed the problem turned out to be in the database adapter library, that he fixed: https://github.com/elixir-ecto/myxql/commit/082febbe5941a6e430680d5c133bc0e74469554d
Conclusion
Even if at first such matters look scary, and may take time and effort to investigate, as well as for sure how many services there are, that many chances of various issues can appear shifting the investigation directions, it totally worth the effort.
Firstly because you kind of have no choice, as these matters cannot be ignored, but second because of the personal satisfaction reward of seeing these issues fixed and knowing you contributed to the stability of the overall platform of you team and maybe as in this case of other teams who had this issue but did not know where to start.