There comes a day when a single search index with a single shard deployed on a single node is no longer enough for satisfying the performance requirements of a growing system. In this article I will not go into the details of discovering the right configuration which has to be put in place for a given context. This would make an entire article in itself.
All I can say, very briefly, is that there is no magic formula which can be generically applied to all the applications which are using search solutions. It always depends on multiple factors which have to be discovered with the right measurements and tests.
You have no choice than to take your search data, put it in an environment where you can test various combinations of nodes, collections, sharding and replication numbers and break each setup with production like queries, until the measurements fit the required ones.
Among the factors which will influence the configuration you will end up with are:
- the number of concurrent reads
- the types of the reads
- the number of concurrent writes
- the types of the writes
- the size of your data
- what other processes happen behind the scenes (services which trigger deletions, exports, you name it)
- and of course the defined NFR(Non Functional Requirements) for your system either if it is a 5s or 0.5s response time
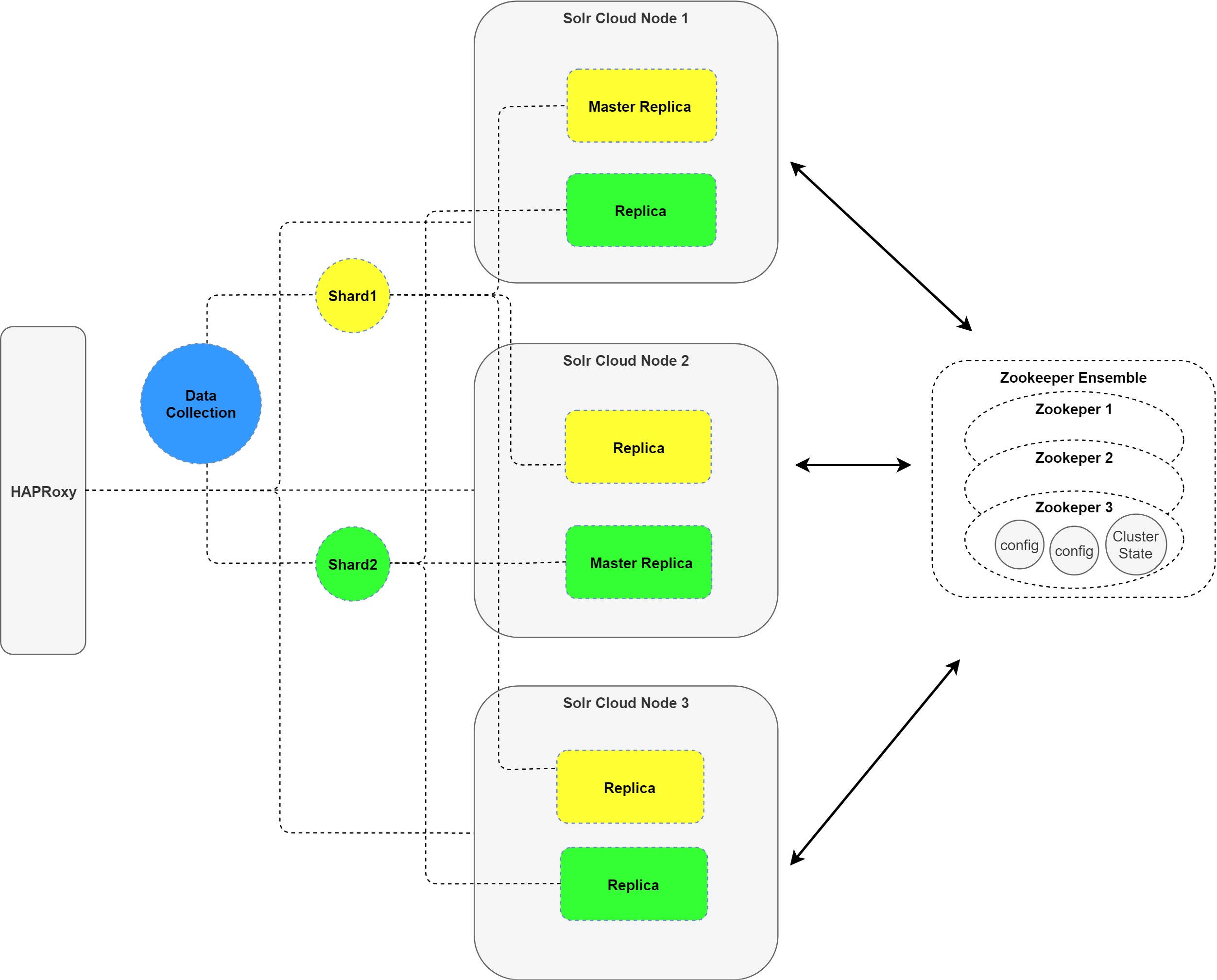
Bellow I will describe how you can setup collections splitted into two shards, replicated on 3 nodes out of which one would be the master and the other two the slaves.
For a good start, I recommend the official documentation from apache: Solr Cloud Taking Solr to Production
Solr Cloud does not maintain the cluster configurations. Therefore, their recommendation is to use an ensemble of zookeeper services for that:
"For a ZooKeeper service to be active, there must be a majority of non-failing machines that can communicate with each other. To create a deployment that can tolerate the failure of F machines, you should count on deploying 2xF+1 machines. Thus, a deployment that consists of three machines can handle one failure, and a deployment of five machines can handle two failures. Note that a deployment of six machines can only handle two failures since three machines is not a majority.
For this reason, ZooKeeper deployments are usually made up of an odd number of machines."
— ZooKeeper Administrator's Guide
http://zookeeper.apache.org/doc/r3.4.10/zookeeperAdmin.html
In our example we will install 3 zookeeper instances.
For balancing the load on our local configuration, we will use HAProxy which will be configured to elect the nodes based on the round robin algorithm.
The goal would be to achieve something like this:
First step consists in configuring the necessary servers with the desired configurations:
#########################################################################
###### Zookeeper1 config ####################################################
#########################################################################
config.vm.define "zookeeper1", autostart: false do |zookeeper1|
zookeeper1.vm.box = "centos/7"
zookeeper1.vm.network "private_network", ip: "10.192.22.40"
#zookeeper1.vm.synced_folder "./zdata1", "/vagrant_data"
zookeeper1.vm.provider "virtualbox" do |vb|
# vb.gui = true
# Don't boot with headless mode
# Use VBoxManage to customize the VM. For example to change memory:
vb.memory = 1024
vb.cpus = 2
end
end
The next step is to implement all the required configurations that will be executed by ansible on the needed network devices.
The inventory files
The list of above installed servers are recommended to be kept in inventory files for each environment you have. There are two formats possible ( check the documentation). The one I will be using here is the INI-like, which is the Ansible default.
They can contain the list of IPs or any other global configuration grouped under different names, put in heading brackets:
In this tutorial, I will name my inventory local_inventory, and I will add the servers deployed with vagrant under the following group names:
solr-a ansible_host=10.192.22.10 ansible_user=vagrant ansible_host_name=10.192.22.10
solr-b ansible_host=10.192.22.20 ansible_user=vagrant ansible_host_name=10.192.22.20
solr-c ansible_host=10.192.22.30 ansible_user=vagrant ansible_host_name=10.192.22.30
zookeeper-a ansible_host=10.192.22.40 ansible_user=vagrant ansible_host_name=10.192.22.40
zookeeper-b ansible_host=10.192.22.50 ansible_user=vagrant ansible_host_name=10.192.22.50
zookeeper-c ansible_host=10.192.22.60 ansible_user=vagrant ansible_host_name=10.192.22.60
haproxy-a ansible_host=10.192.22.70 ansible_user=vagrant ansible_host_name=10.192.22.70
[lbservers]
haproxy-a
[zkservers]
zookeeper-a zookeeper_myid=0
zookeeper-b zookeeper_myid=1
zookeeper-c zookeeper_myid=2
[mainsolrserver]
solr-a solr_host=10.192.22.10
[webservers]
solr-a solr_host=10.192.22.10
solr-b solr_host=10.192.22.20
solr-c solr_host=10.192.22.30
[lbservers:vars]
lbcertificate=haproxy.pem
enable_haproxy_connect=yes
[webservers:vars]
current_user=g
kits_path=/home//kit/
validate_certs=yes
enable_ports=yes
create_collections=yes
copy_cert_automatically=yes
solrcertificate=solr-ssl.local.keystore
solrcertificatesecret=secret
solr_ui_admin_user=test
solr_ui_admin_pass=test
solr_zookeeper_hosts="10.192.22.40,10.192.22.50,10.192.22.60"
solr_zookeeper_host=10.192.22.40
solr_main_server=10.192.22.10
solr_java_mem="-Xms512m -Xmx1g"
The group_vars
For the group names in the inventory, global variables can be defined which will be applied to all inventories on which the ansible playbook will be executed on.
The convention is to create a folder named group_vars and have files named with the group names from the inventory. This way, Ansible will know to retrieve and apply them inside the roles.
Example: File name: group_vars\lbservers
#Role haproxy vars
haproxy_archive_name: "haproxy-1.5.18-6.el7.x86_64.rpm"
haproxy_installation_folder: /opt
haproxy_path_name: "haproxy-1.5.18"
haproxyowner: haowner
haproxygroup: hapass
The Playbooks
The Playbooks are the ansible’s configuration, deployment and orchestration language. A playbook will contain in the end the complete suite of tasks which have to be deployed and configured on a list of remote machines.
The recommendations I have for it is to:
- Name all the tasks in it, during the run it will be easier to know details regarding the execution progress
- Keep it simple for readability and clarity
- Group the configurations by roles
- Use tags - this way you can choose to deploy only a subset of configurations from the playbook
In our particular case, the roles which will end up in the playbook can be splitted into the following list:
- the prerequisites
- the haproxy
- the zookeeper
- for the solrcloud, the recommendation is to be splitted in at least two roles: one for deploying the service and another one for uploading or changing the collections configurations. This way later, when only the configuration changes, but the service is already installed, the playbook can be executed with the tagname
solrcloudconfigs
My playbook is named solrcloud-playbook.yml. Inside it, for each of the above mentioned task, the content will be similar to:
- name: HAProxy
hosts: lbservers
become: yes
roles:
- haproxy
tags:
- haproxy
Once all the configurations are in place, the following command can be executed:
$ ansible-playbook -i local_inventory solrcloud-playbook.yml --extra-vars "current_user=test" -t tagname
The Roles
Examples of haproxy roles:
Examples of zookeeper roles:
Examples of solrcloud roles: